Rune 0.13
- John-John Tedro
- 2091 words
- 11 min
Welcome to the official release of Rune 0.13!
Rune is an embeddable dynamic programming language for Rust, it seeks to mimic the way rust works and is structured. A common way to describe it is "Rust without types".
For a quick overview:
- Modular commandline.
- Code formatting.
- Generating documentation.
- Workspace support.
- Breaking changes to native functions.
- Memory sandboxing and
rune-alloc. #[no-std]support- Migrating
- Other important changes
Modular commandline
A common problem in Rune is that the CLI we build for it only comes with our own set of modules. That isn't primarily how rune is supposed to work. You plug in your own context and use that to build and analyze your scripts.
With the release of 0.13 we've made the CLI of rune into a module into which you
can build your own CLI with your own context. All you need to do is set up a
Rust project which depends on your project and rune with the cli feature
enabled.
[package]
name = "my-project-cli"
[dependencies]
rune = { version = "0.13.0", features = ["cli"] }
my_project = { path = "../my_project" }
And then you configure and run it like so:
const VERSION = "0.13.0";
fn main() {
rune::cli::Entry::new()
.about(format_args!("My Rune Project {VERSION}"))
.context(&mut |opts| {
Ok(my_project::setup_rune_context()?)
})
.run();
}
Once you've done this, you can configure the Rune extension in vscode to use this project through cargo rather than the normal rune-cli.

Code formatting
We have a new CLI subcommand capable of performing code formatting called rune fmt. This can both take individual files and format the workspace:
== scripts\arrays.rn
++ scripts\async.rn
5 let timeout = time::sleep(time::Duration::from_secs(2));
6
7 let result = select {
8 - _ = timeout => Err(Timeout ),
+ _ = timeout => Err(Timeout),
9 res = request => res,
10 }?;
11
Generating documentation
Good documentation is one of these features which is crucial when using a language for embedding. Without some reference it's hard to know which methods and types are available for use.
We strongly believe in the idea that documentation should live close to the code
being documented so Rune now has the ability to generate api documentation from
declared modules. This is aided by the introduction of a few attribute macros
like #[rune::function], #[rune::macro_].
The following is part of the declaration of our built-in std::char module:
pub fn module() -> Result<Module, ContextError> {
let mut module = Module::with_crate_item("std", ["char"]);
module.instance_function(is_alphabetic)?;
/* ... */
Ok(module)
}
#[inline]
fn is_alphabetic(c: char) -> bool {
char::is_alphabetic(c)
}
Now we can change it into this, and register the function using function_meta
to associate Rust doc comments with the function (documentation borrowed from
Rust):
pub fn module() -> Result<Module, ContextError> {
let mut module = Module::with_crate_item("std", ["char"]);
module.function_meta(is_alphabetic)?;
/* ... */
Ok(module)
}
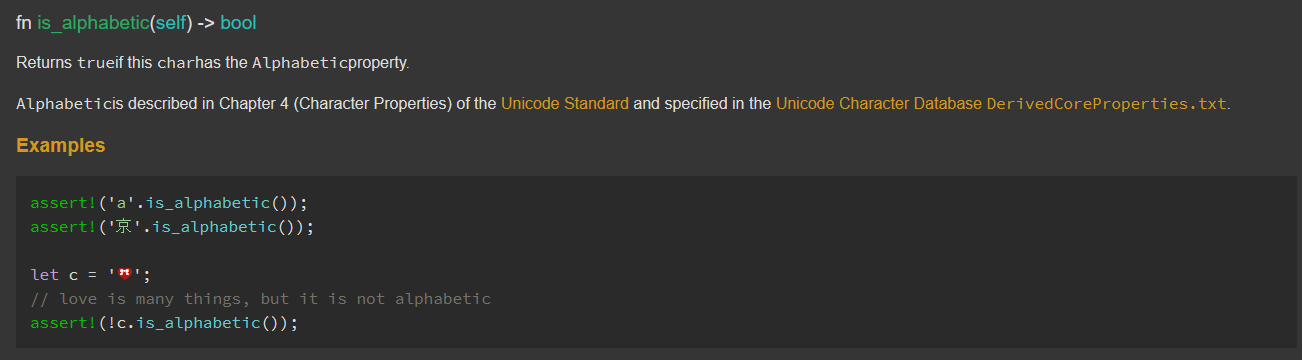
/// Returns `true` if this `char` has the `Alphabetic` property.
///
/// `Alphabetic` is described in Chapter 4 (Character Properties) of the [Unicode Standard] and
/// specified in the [Unicode Character Database][ucd] [`DerivedCoreProperties.txt`].
///
/// [Unicode Standard]: https://www.unicode.org/versions/latest/
/// [ucd]: https://www.unicode.org/reports/tr44/
/// [`DerivedCoreProperties.txt`]: https://www.unicode.org/Public/UCD/latest/ucd/DerivedCoreProperties.txt
///
/// # Examples
///
/// ```rune
/// assert!('a'.is_alphabetic());
/// assert!('京'.is_alphabetic());
///
/// let c = '💝';
/// // love is many things, but it is not alphabetic
/// assert!(!c.is_alphabetic());
/// ```
#[rune::function(instance)]
#[inline]
fn is_alphabetic(c: char) -> bool {
char::is_alphabetic(c)
}
Using rune doc --open we now get the documentation we expect:
Now also if rune test, it will pick up and run all documentation tests it can
find:
#> rune test
...
Test ::std::bytes::Bytes::capacity: ok
Test ::std::bytes::Bytes::clear: ok
Test ::std::bytes::Bytes::reserve: ok
Test ::std::bytes::Bytes::reserve_exact: ok
Test ::std::bytes::Bytes::clone: ok
Test ::std::bytes::Bytes::shrink_to_fit: ok
Test ::std::any::type_name_of_val: ok
Test ::std::any::Type::of_val: ok
Test ::std::any::Type: ok
Executed 412 tests with 0 failures (0 skipped, 0 build errors) in 2.756 seconds
We now use this on top of our already extensive test suite to test Rune itself.
If you want to see the documentation that is available for Rune's built-in modules, see: https://rune-rs.github.io/docs/std.module.html.
Preliminary workspace support
The CLI can now be told where Rune sources are located using a similar concept to Rust workspaces.
This is done by adding a Rune.toml in your project, and pointing out any
submodules which might contain other sources:
[workspace]
members = [
"benches",
"examples",
]
Each project then specifies their own Rune.toml, uniquely identifying the component:
[package]
name = "rune-benches"
version = "0.0.0"
For not it's only used to automatically locate tests, benchmarks, examples, and
bins so they can be used with the rune rune --example <name> command. But will
be extended in the future.
Breaking changes to native functions
See issue #601.
Due to a soundness issues the way native functions are registered has been changed.
In Rune we can use references in function calls, but they are not allowed to
outlive the function call from where it originates. Unfortunately due to how
function bindings were built we would accept functions which uses references
that outlives the function call such as 'static references:
fn download(url: &'static str) {
std::thread::spawn(move || {
dbg!(url);
});
}
An unfortunate side effect is that the future produced by asynchronous functions no longer can capture references. Even though this is perfectly sound the way that Rune uses them, there's no way to model this correctly:
#[rune::function]
async fn download(url: &str) {
/* .. */
}
Such a function now instead has to be written using a managed reference like
Ref<T> or Mut<T> like this:
#[rune::function]
async fn download(url: Ref<str>) {
/* .. */
}
Memory sandboxing and rune-alloc
Sandboxing in general is still work in progress. As with everything in Rune, it comes without warranty.
The internal data structures of rune used to, as most Rust programs do, rely on alloc containers.
But what if you want to limit the amount of memory a Rune call is allowed to take?
One approach might be to install a global allocator which keeps track of the amount of memory in use. An issue here is that any allocation error from the perspective of the container is seen as a fatal problem which will cause the process to abort.
The approach we took with Rune instead is to write our own set of collections.
Or rather fork the ones in std and hashbrown that we care about.
This affords us a couple of things which regular containers do not allow for:
- Each operation that might allocate is fallible, so we can simply error instead of abort the process on allocation errors.
- We can provide raw iterators over these collections that do not take a lifetime, so that they can be integrated better into the rune iterator system1.
- We can modify the containers so that they don't require the value being stored in them to implement a certain set of traits. Or in other words, dynamic values can be stored in them.
This currently includes many containers need to clone their entire content as they're being iterated over.
Now we have basic support for limiting the amount of memory a process is allowed
to use through rune::alloc::limit, as long as the rune-alloc types are being
used:
use rune::alloc::limit;
use rune::alloc::Vec;
let f = limit::with(1024, || {
let mut vec = Vec::<u32>::new();
for n in 0..256u32 {
vec.try_push(n)?;
}
Ok::<_, rune::alloc::Error>(vec.into_iter().sum::<u32>())
});
assert!(f.call().is_err());
This comes with some caveats, the biggest being that allocator metadata is not taken into account. A clever adversary might be able to use this to their benefit by say performing many small allocations.
See the rune::alloc::limit documentation for more information, including
further limitations.
#[no-std] support
With a bit of effort, you can now use Rune in a no-std environment assuming you have access to an allocator and a bit of muscle grease.
See the no-std project for how it can be done.
Migrating
This will be expanded to include information on how to migrate from 0.12.x to 0.13.x as particular pain points are found.
There is a lot of minor changes, so please bare with us!
The introduction of VmResult<T>
See issue #478.
Errors in the Rune virtual machine are known as panics. In contrast to Rust, such panics do not cause the whole process to abort, but will only cause the current virtual machine execution to error.
Previously this was modelled by having any such fallible functions using
Result<T, VmError>. Implementing certain traits for such a type is
problematic. For example the TypeOf implementation for Result<T, E> should
indicate that it's a dynamic result type, while Result<T, VmError> should
propagate the type of T:
impl<T, E> TypeOf for Result<T, E> {
fn type_of(&self) -> Type {
/* type of the dynamic Result */
}
}
// This implementation should propagate the type of `T`, but conflicts with the above implementation.
impl<T, E> TypeOf for Result<T, VmError> where T: TypeOf {
fn type_of(&self) -> Type {
T::type_hash()
}
}
This makes it impossible to build a blanket implementation that can distinguish
between functions which panics by returning a Result<T, VmError> and results
we want to propagate into Rune.
To bridge this gap Rune has introduced a special result type called
VmResult<T>. This is exclusively used to propagate virtual machine panics and
means that implementations can cleanly distinguish between results and panics.
Unfortunately this result type can't use the regular try operator (?) since
try_traits_v2 is not yet
stable. To bridge this rune
provides the vm_try! macro which behaves like the now deprecated try! macro.
#[rune::function(instance, path = collect::<Vec>)]
fn collect_vec(it: Iterator) -> VmResult<Vec> {
VmResult::Ok(Vec::from(vm_try!(it.collect::<Value>())))
}
Changes to Any
See #509.
Anything deriving Any and is defined inside of a module will need to make use
of #[rune(item = ..)] to generate the correct type hash. This is done to
remove a bit of unsafe involving assumptions about std::any::TypeId, which
could lead to unsoundness if Rust decides to change its implementation in the
future.
So this:
#[derive(Any)]
struct Process {
/* .. */
}
fn install() -> Result<rune::Module, rune::ContextError> {
let mut module = rune::Module::with_crate("process");
module.ty::<Process>()?;
Ok(module)
}
Will have to have its #[rune(item = ..)] setting specified like this:
#[derive(Any)]
#[rune(item = ::process)]
struct Process {
/* .. */
}
For non-crate modules, the path should be specified without the leading ::.
Macro attributes takes identifiers instead of strings
See #509.
Macros now take paths and identifiers instead of strings, so this:
#[rune(name = "Foo")]is now#[rune(name = Foo)].#[rune(install_with = "path::to::function")]is now#[rune(name = path::to::function)].#[rune(module = "rune2")]is now#[rune(module = rune2)].
Other important changes
- Integer types have been rename to match their rust equivalents:
byteis now namedu8.intis now namedi64.floatis now namedf64.
- As a result of the above, some module renames have taken place:
std::intmodule has been renamedstd::i64.std::floatmodule has been renamedstd::f64.
- Literal operators with type hints are now supported:
10u8would correlate to abyte, which is now known asu8.10i64would correlate to anint, which is now known as ai64.10f64would correlate to afloat, which is now known as af64.
- Coerce operator
<value> as <type>are now supported, such as:1u8 as f64. Its behavior matches exactly that of Rust but is for now only supported with the existing built-in types.